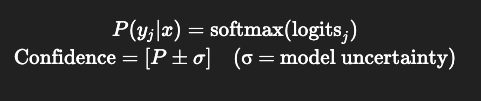Project Name
Comreton AI - Transparent & Auditable AI Marketplace
Problem Statement
Today’s AI systems are largely black boxes—users can’t inspect how models make decisions, whether they’re fair, or if they’re even functioning as advertised.
Developers lack transparent, on-chain tools to monetize their models, while users, researchers, and regulators have no way to independently audit performance, safety, or bias.
This lack of transparency erodes trust, reinforces centralized control by a few tech giants, and limits open innovation in the AI ecosystem.
Solution Overview
Comreton AI reimagines AI as a transparent, trustless public good by making every inference step—down to individual neural network layers—verifiable on-chain.
We introduce a universal model standard and SDK that converts popular AI models into blockchain-executable formats without sacrificing performance or auditability.
Before going live, models are peer-reviewed by community auditors who stake tokens, ensuring safety, fairness, and compliance.
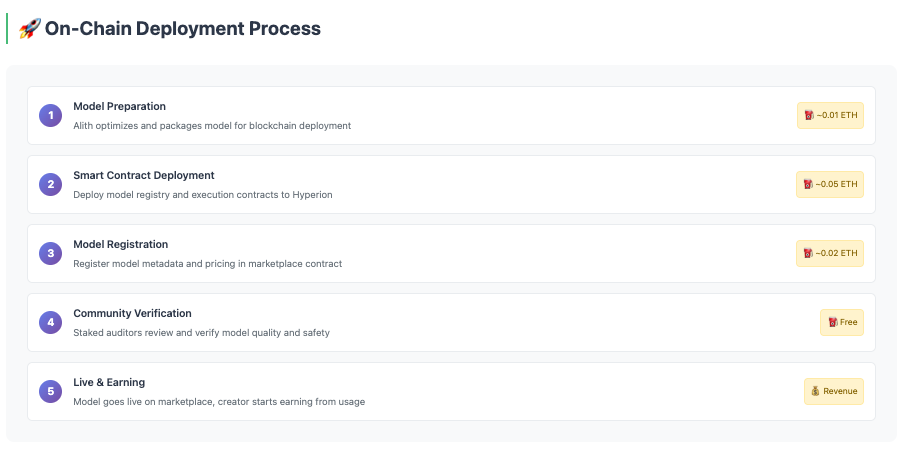
Once verified, models are deployed on-chain via Alith’s optimized infrastructure, enabling secure, fee-based access for users.
This creates a fully decentralized AI marketplace where creators earn sustainably, auditors uphold quality, and users gain access to transparent, provably fair AI models they can trust.
Project Description
Comreton AI is building the world’s first transparent and auditable AI marketplace, powered by the Hyperion blockchain and optimized through Alith’s on-chain inference engine.
Today, AI functions like a black box—users can’t verify how decisions are made, developers struggle to monetize models fairly, and trust is continually eroded. We’re solving that.
Core Functionality:
- On-Chain Transparency: Every layer of an AI model runs on-chain and emits verifiable proofs, enabling anyone to audit the model’s behavior step-by-step.

-
Universal Model Conversion: Our SDK converts models from TensorFlow, PyTorch, or ONNX into a blockchain-executable format—with auditability built in from day one.
-
Decentralized Quality Control: Community auditors stake tokens to review models for bias, safety, and performance before they go live—ensuring integrity without gatekeepers.
-
Sustainable AI Economy:
- Creators earn 40% of every inference fee.
- Auditors are rewarded for verifying model quality.
- Users pay a small, fair price for AI they can trust.

Tech Stack & Architecture:
- Execution Layer: Hyperion + MetisVM for parallelized, high-speed smart contract execution
- Optimization Engine: Alith (Rust-based) for compiling and compressing models into blockchain-efficient formats
- Storage: IPFS for decentralized model file storage
- Smart Contracts: For model registration, staking, inference payments, and reputation management

How Users Interact:
- Creators: Upload models via our SDK and choose pricing. We handle the rest—optimization, registration, and listing.
- Auditors: Stake tokens to review models. Earn rewards for honest, accurate verification.
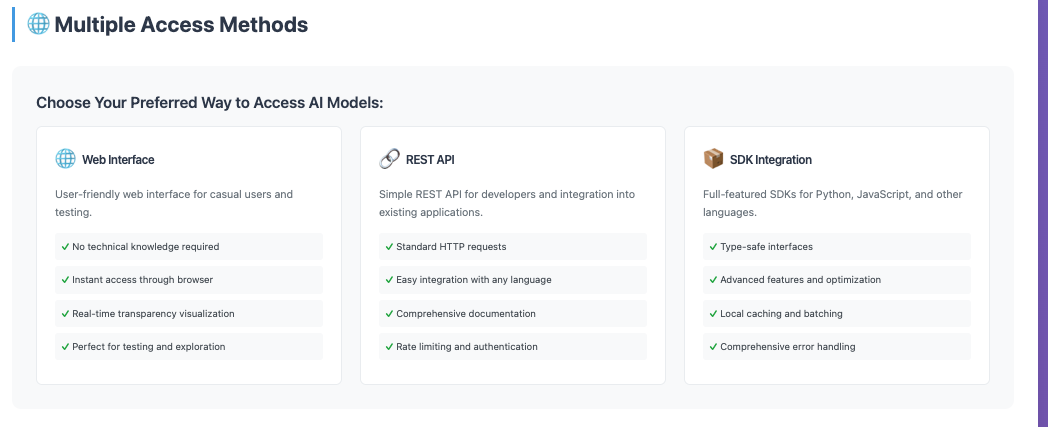
- End Users: Browse models like an app store. Run AI with one click, without needing compute—results are delivered verifiably and transparently.
What Excites Us:
Comreton AI turns opaque, centralized AI into a provable, community-owned infrastructure. Imagine verifying—mathematically—that:
- A hiring model isn’t biased by gender.
- A medical diagnosis AI followed best practices.
- A financial model acted fairly and consistently.
We’re not just building another AI tool—we’re building the foundation of trust for AI’s future.
Community Engagement Features
Our platform is designed to onboard and retain users through gamified participation and collaborative incentives:
- Creator Track: Upload models, convert them to our transparent format, and earn revenue as your models gain usage and trust.
- Auditor Track: Review models for integrity, stake tokens to verify quality, and build your reputation as a trusted AI auditor.
- User Track: Run inferences, explore different models, share feedback, and refer others to grow the ecosystem.
To make this fun and rewarding:
- Leaderboards spotlight top contributors weekly.
- Achievement Badges & NFTs mark important milestones.
- Tiers & Challenges unlock new benefits and recognition.
- Social Sharing builds community visibility and collaboration.
Getting Involved
- AI Creators: Upload and monetize your models using our SDK and transparent deployment tools.
- Auditors: Join the verification process, stake to review models, and earn by ensuring AI integrity.
- Developers: Contribute to open-source components,tooling, and ecosystem integrations.
- Users: Use, Explore, test, and give feedback on models—help shape a trustworthy AI future.